What are the steps to build a decision tree?
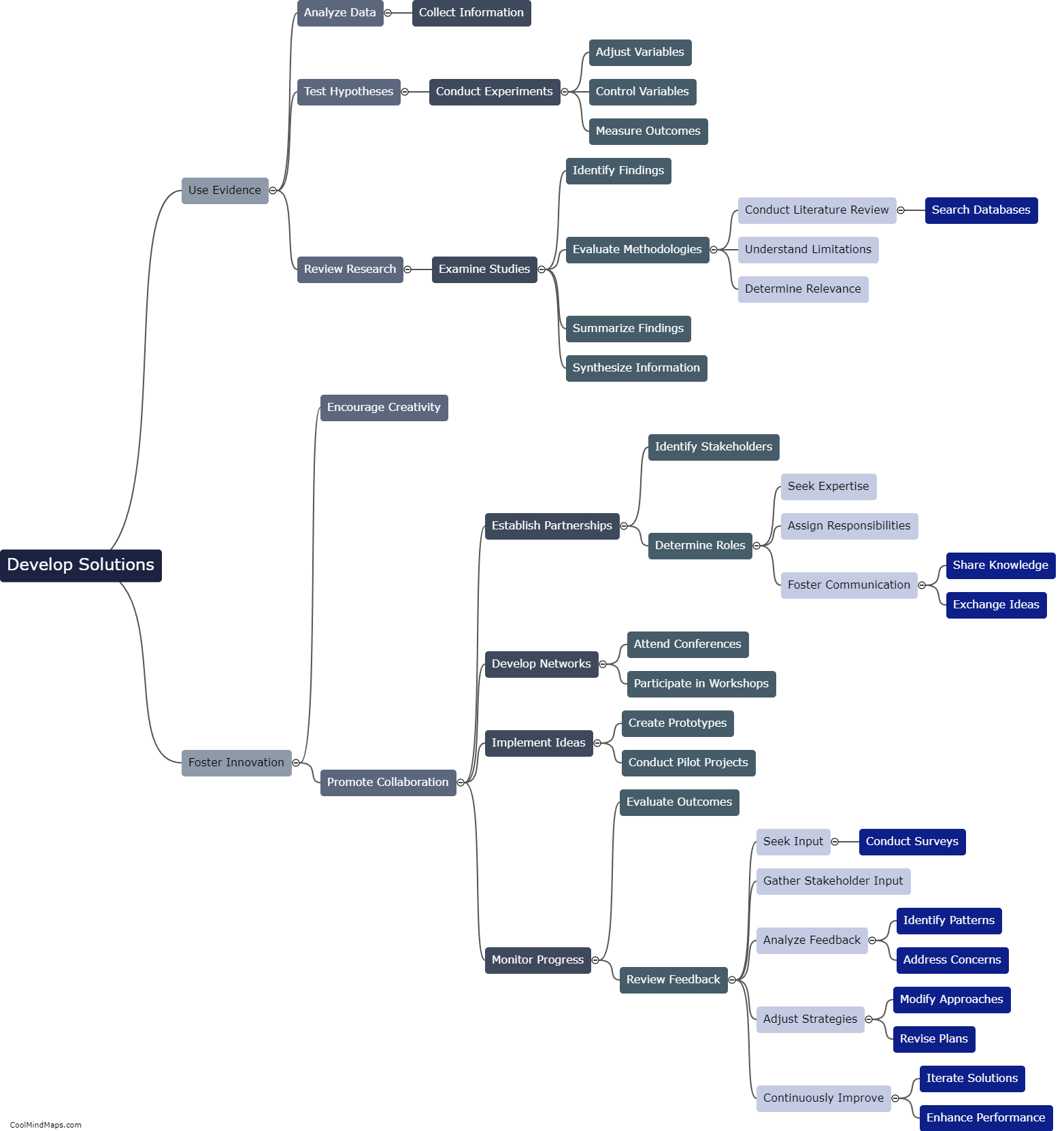
The process of building a decision tree involves several steps. Firstly, you need to gather a relevant dataset that contains both input variables and the corresponding target variable. Next, you must carefully choose an appropriate algorithm to use for constructing the decision tree. Once the algorithm is selected, you can begin the process of training the tree by analyzing the dataset and finding the best splits for each decision node. This involves calculating different metrics such as entropy or Gini impurity to evaluate the quality of each potential split. After determining the best split, you split the dataset into subsets for each branch of the tree and repeat the process recursively until reaching a stopping criterion. Lastly, you can validate and prune the tree to avoid overfitting and improve its generalization abilities. By following these steps, you can create an efficient and accurate decision tree that can be used for making predictions or classifying new data instances.

This mind map was published on 20 December 2023 and has been viewed 86 times.