What are the potential challenges or limitations of data masking in testing?
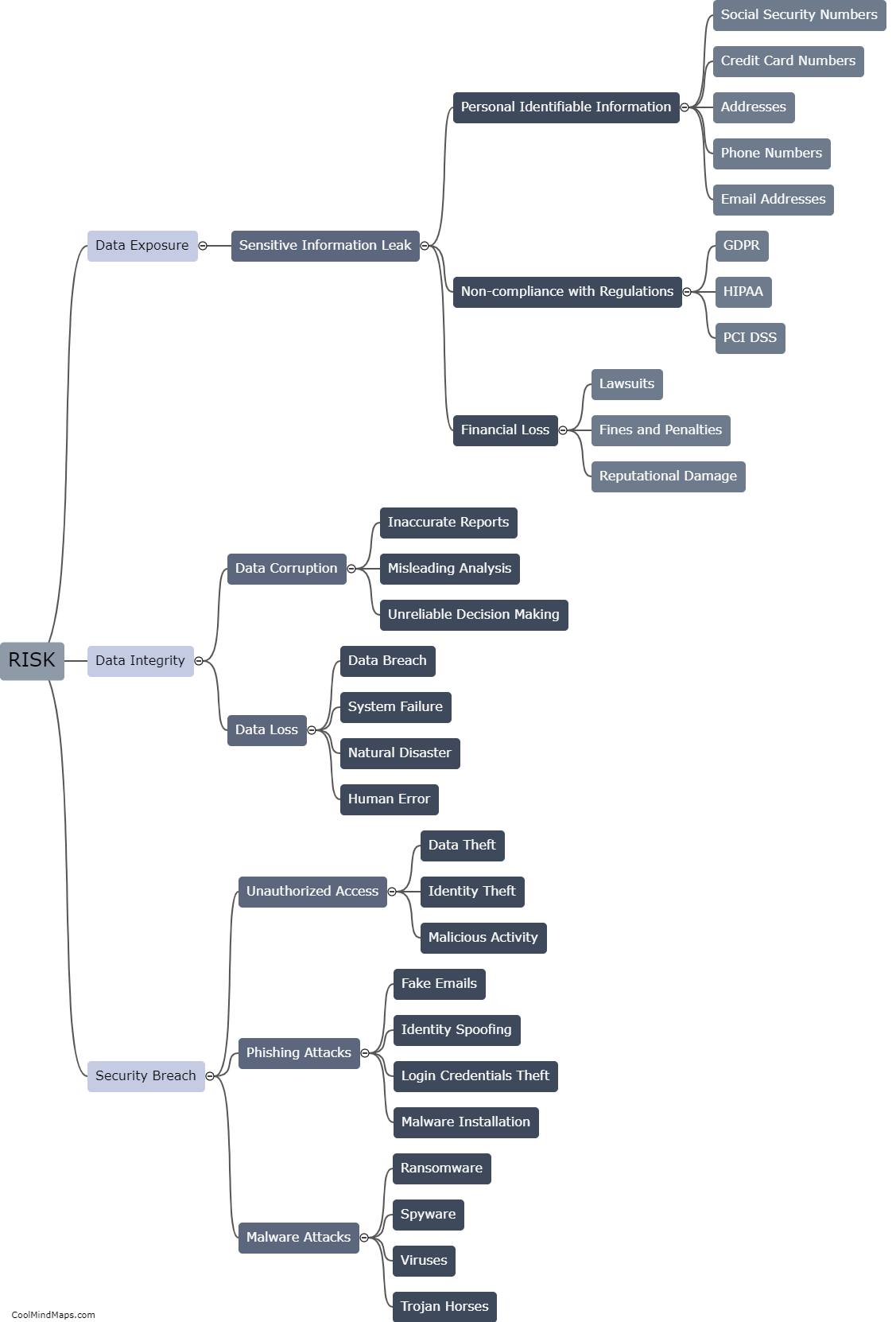
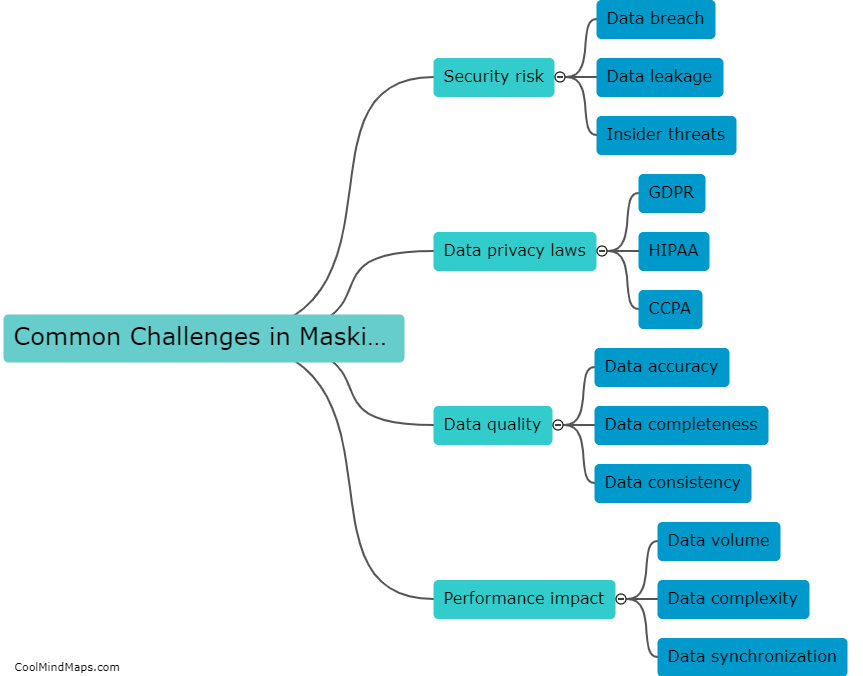
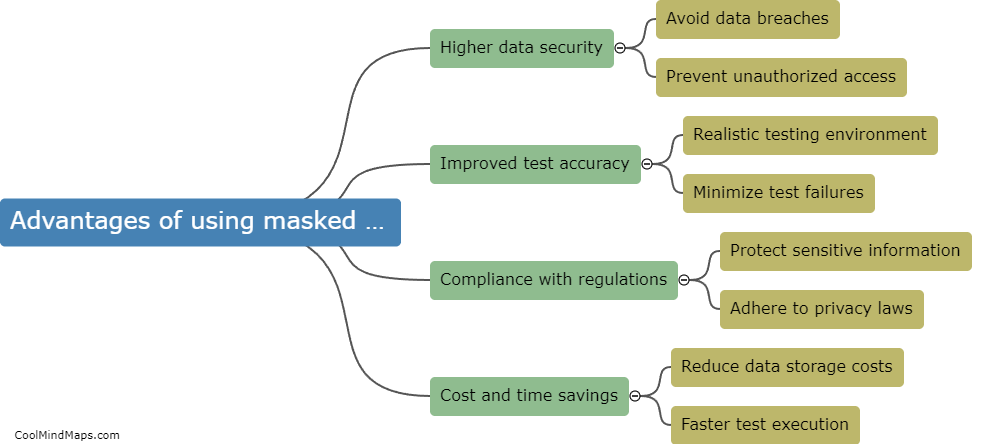
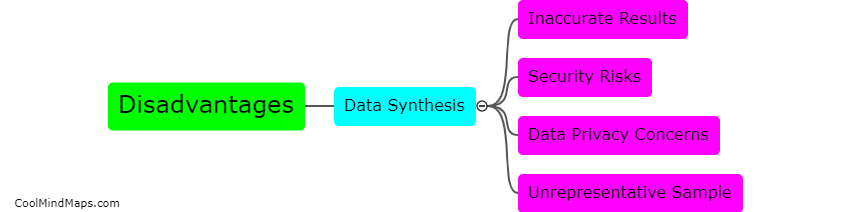
Data masking is the process of substituting sensitive data with realistic but fictional data during testing, in order to protect privacy and maintain data security. However, there are several challenges and limitations associated with data masking. Firstly, it can be difficult to accurately mimic realistic data without compromising its usefulness for testing. Second, existing relationships between multiple data elements can be lost or altered, leading to inaccurate results during testing. Third, the masking process itself can be time-consuming and resource-intensive, potentially slowing down the testing process. Furthermore, data masking may not always be foolproof, with the possibility of data leakage or the reverse engineering of masked data. Finally, maintaining data consistency and integrity across different testing environments can also be a challenge. Despite these limitations, effective data masking strategies and careful consideration of these challenges can help address these issues and ensure successful testing while preserving data privacy.

This mind map was published on 27 July 2023 and has been viewed 120 times.