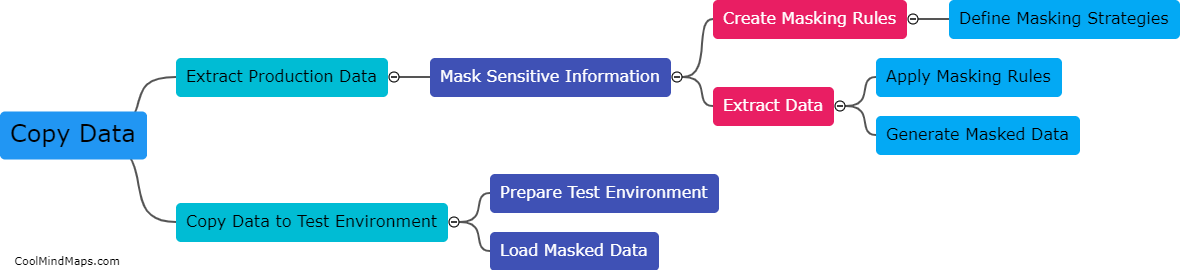
How is data synthesis performed in a test environment?
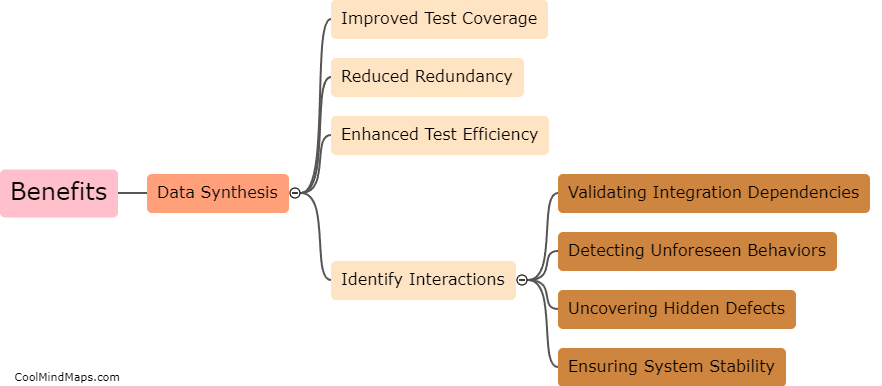
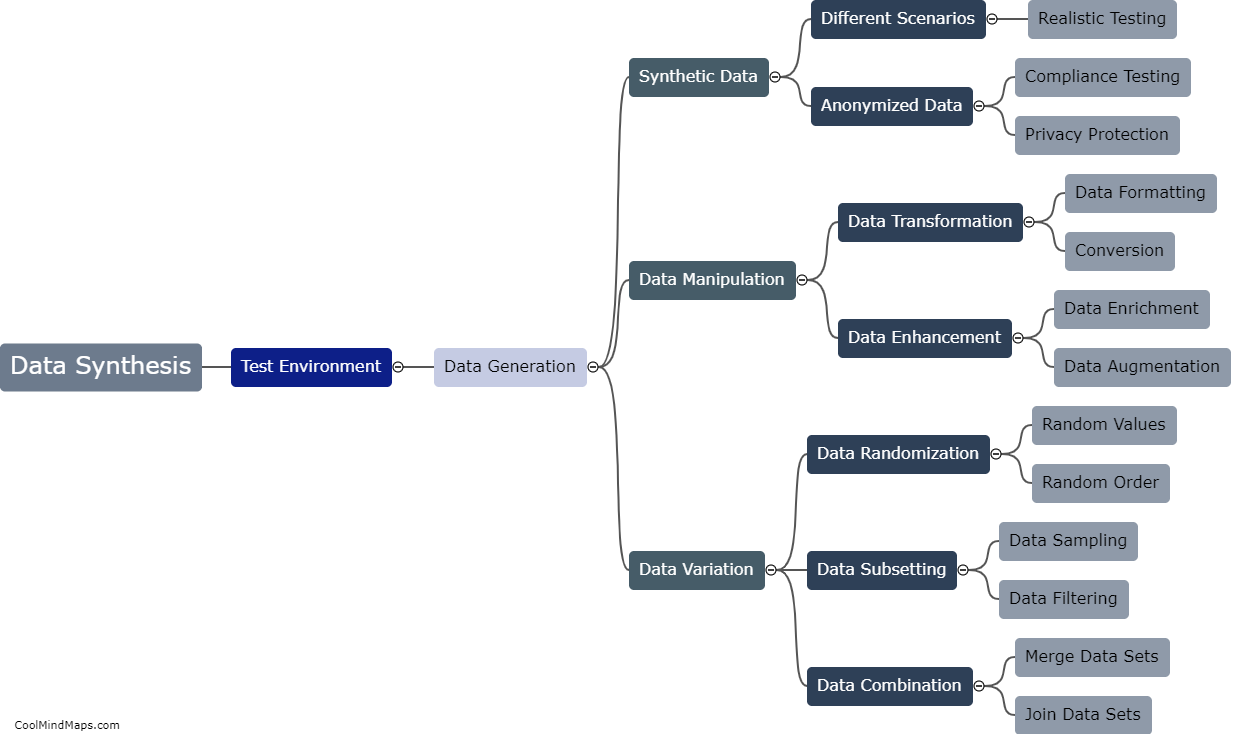
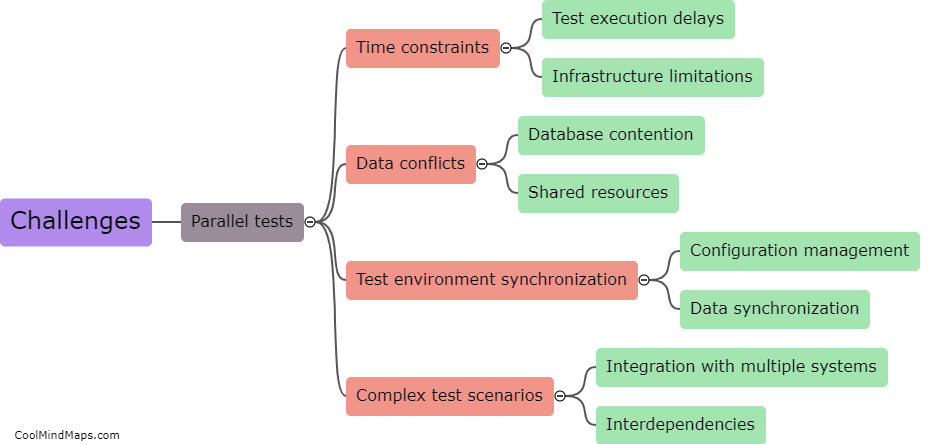
In a test environment, data synthesis refers to the process of generating synthetic or simulated data that closely resembles real-world data. This is done to create realistic scenarios for testing and validating the functionality, performance, and security of software applications or systems. Data synthesis in a test environment can be performed using various techniques such as data generation algorithms, mathematical models, or machine learning algorithms. These methods help in creating diverse datasets that cover a wide range of possible inputs, ensuring thorough testing and evaluation of the system's capabilities. By synthesizing data, testers can simulate different scenarios, identify potential issues or vulnerabilities, and make informed decisions in a controlled environment before deploying the software or system in the real world.

This mind map was published on 27 July 2023 and has been viewed 126 times.