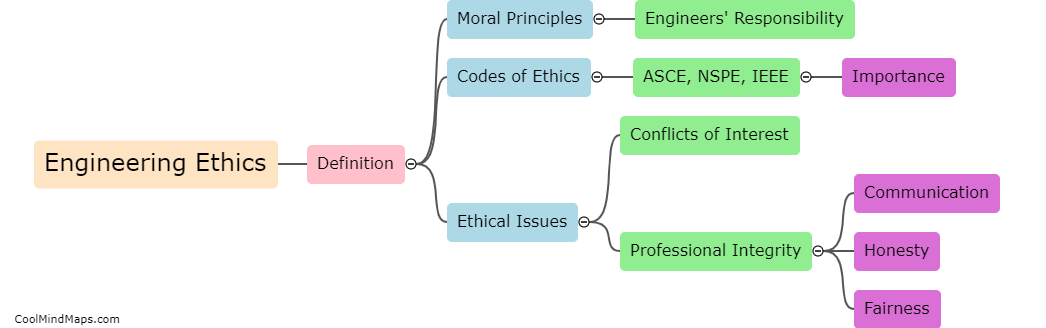
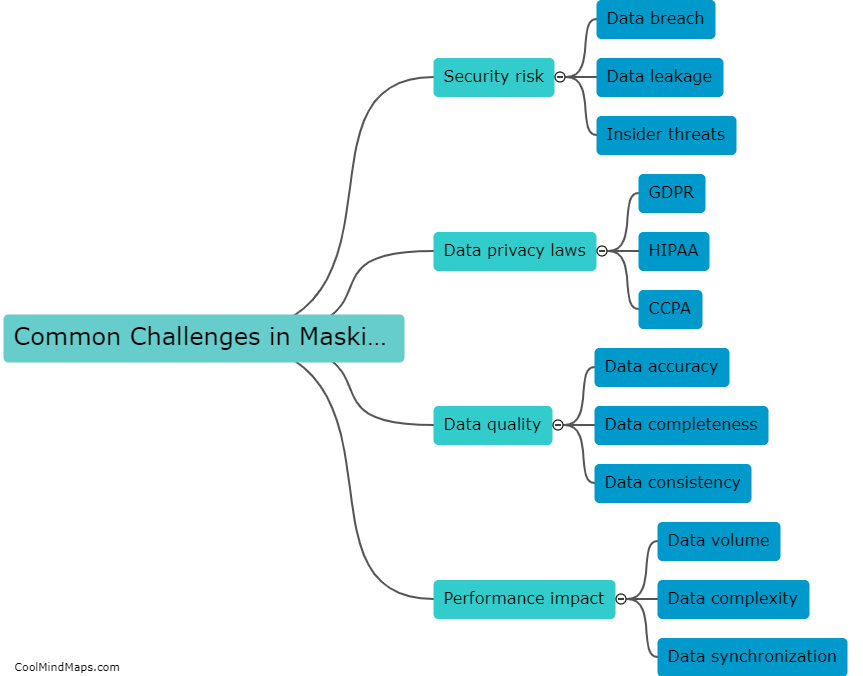
How does data masking impact the accuracy of testing?
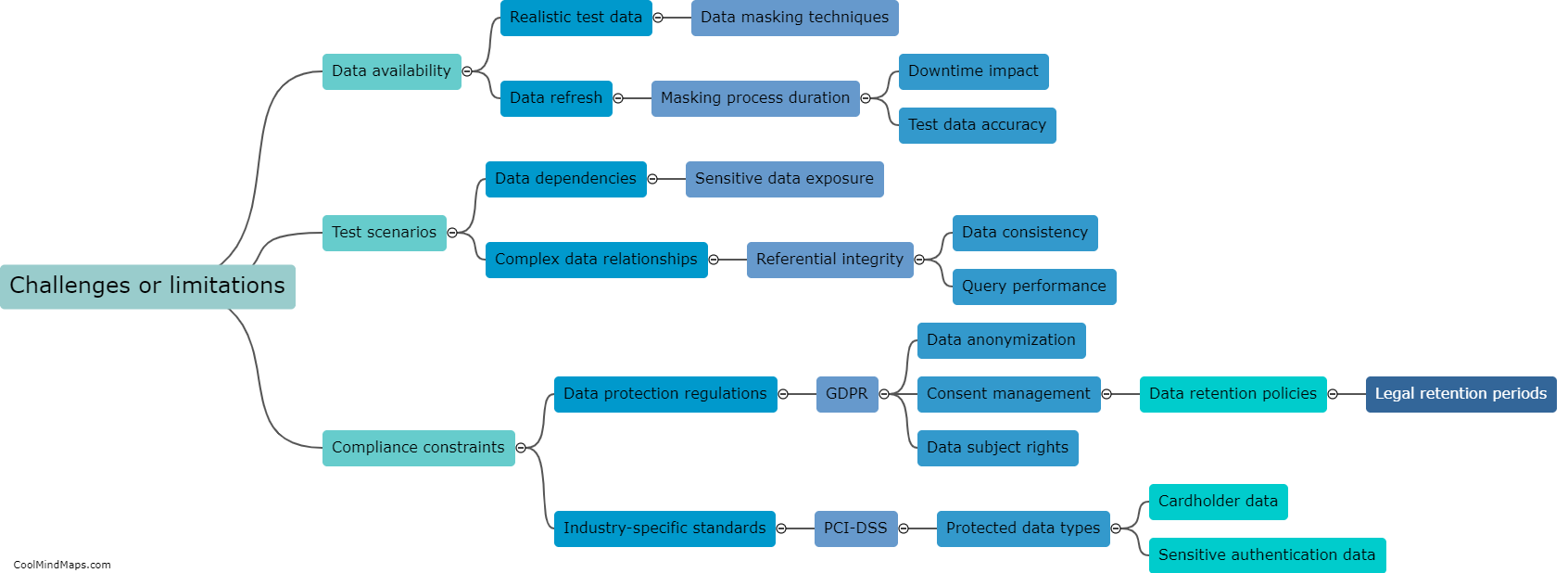
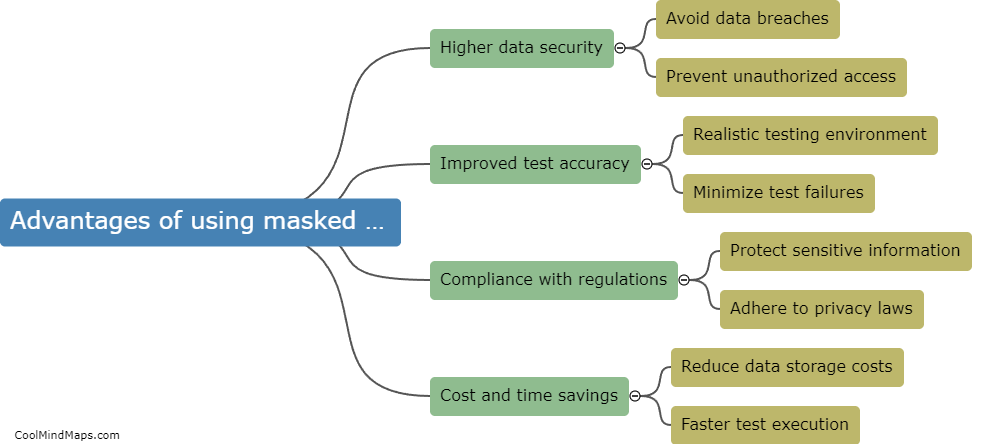
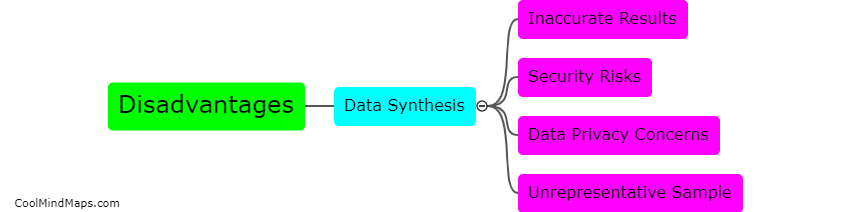
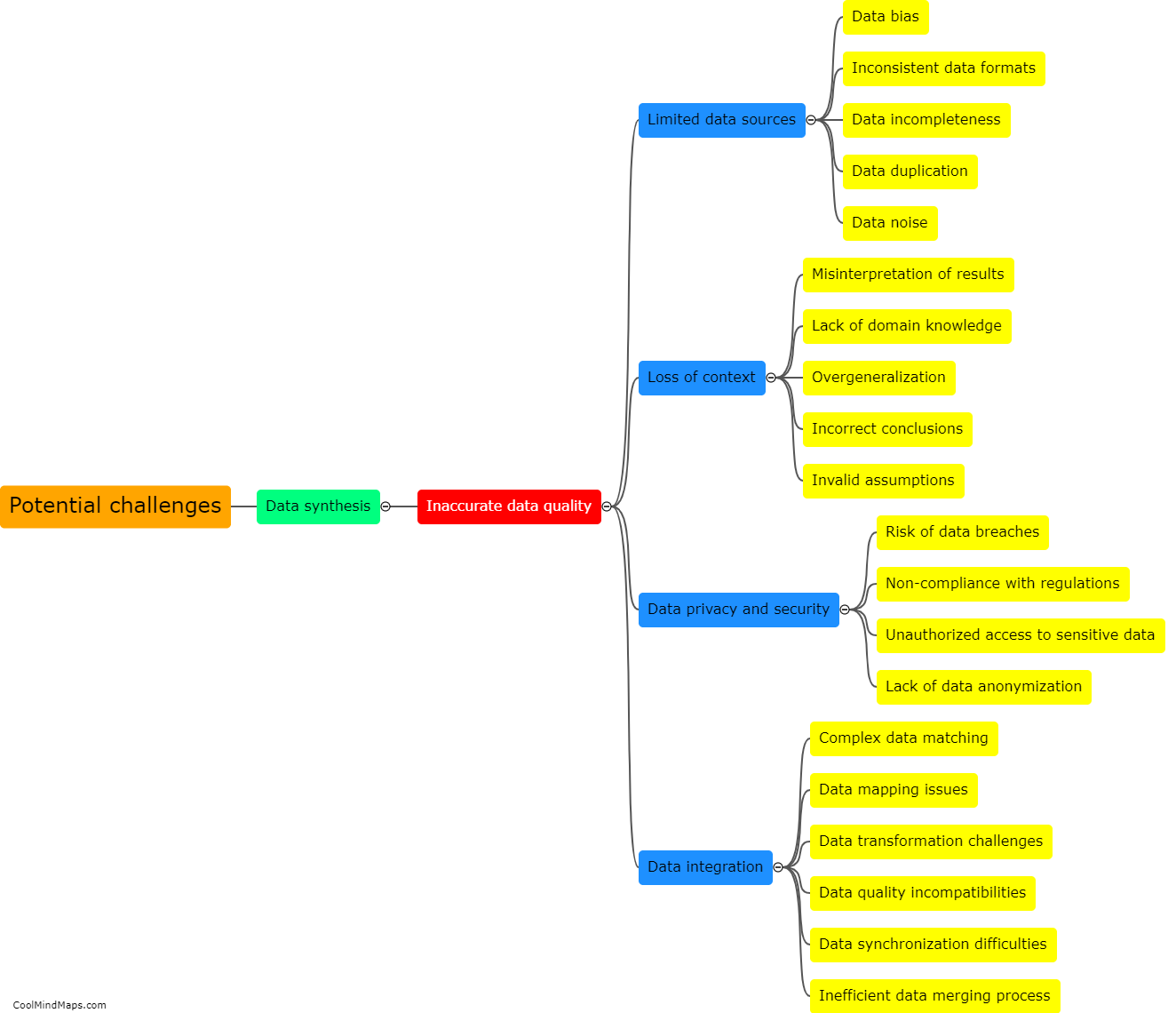
Data masking is a technique used to hide sensitive or personally identifiable information within a database while preserving its usefulness for testing purposes. By replacing actual values with fictional, anonymized, or scrambled data, organizations can protect the privacy of their customers or users. However, data masking can have an impact on the accuracy of testing. The primary concern is that the substituted data may not accurately reflect the characteristics or behavior of the original data, potentially leading to false test results. It is crucial for testers and developers to understand the potential limitations of data masking and carefully validate the substituted data's relevance to ensure the accuracy of the testing process.

This mind map was published on 27 July 2023 and has been viewed 132 times.