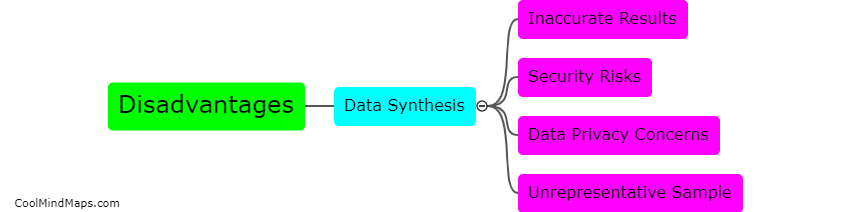
What potential challenges arise when using data synthesis in test environments?
When using data synthesis in test environments, there are several potential challenges that may arise. Firstly, ensuring the quality and accuracy of synthesized data can be difficult. Since this data is usually generated by algorithms or models, there is a risk of introducing biases or errors into the synthesized data. Additionally, it can be challenging to create data that accurately represents the real-world scenarios and variability that may occur in production environments. Another challenge is scalability - as the size and complexity of datasets grow, it becomes increasingly difficult to generate synthetic data that adequately captures the characteristics of the original data. Lastly, maintaining data privacy and security becomes crucial when dealing with sensitive or confidential information, as there is a risk of exposing sensitive data when synthesizing test datasets. Overall, careful consideration and validation are necessary to overcome these challenges and ensure the effective use of data synthesis in test environments.

This mind map was published on 27 July 2023 and has been viewed 104 times.