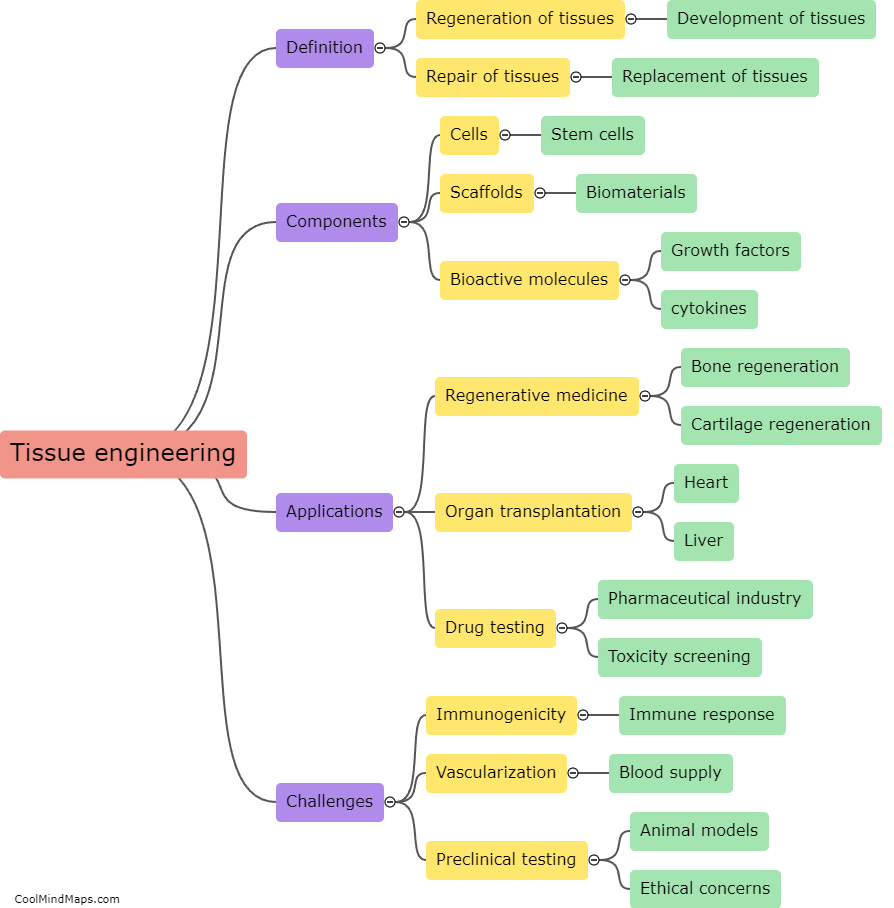
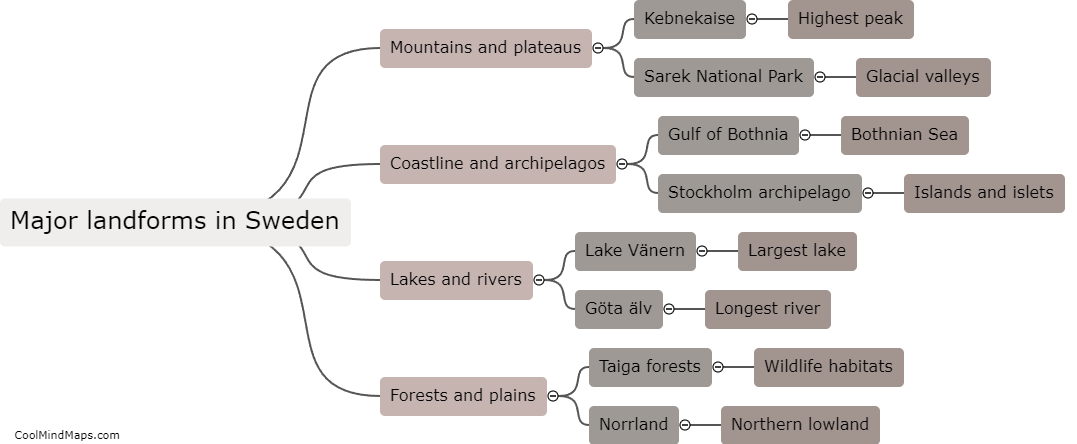
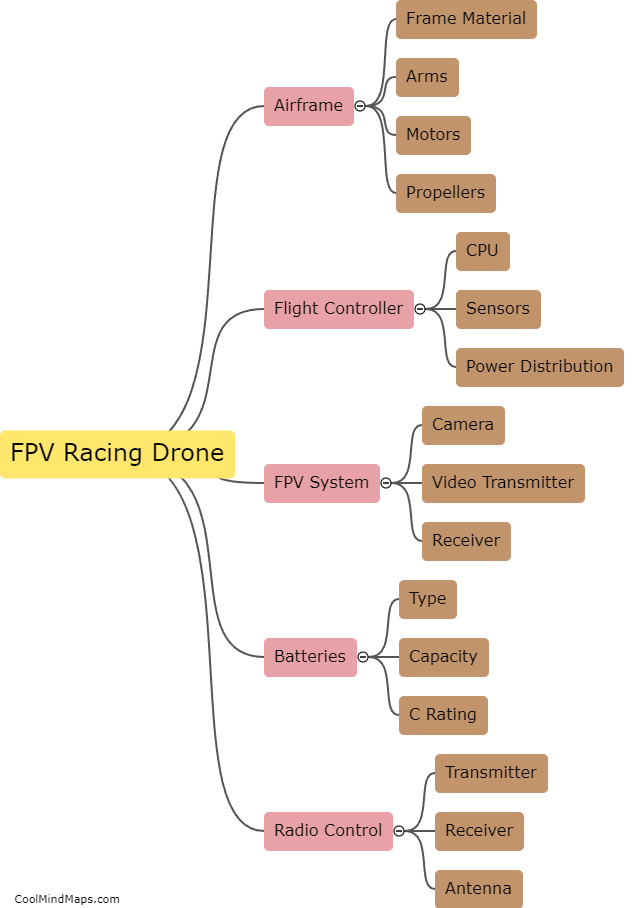
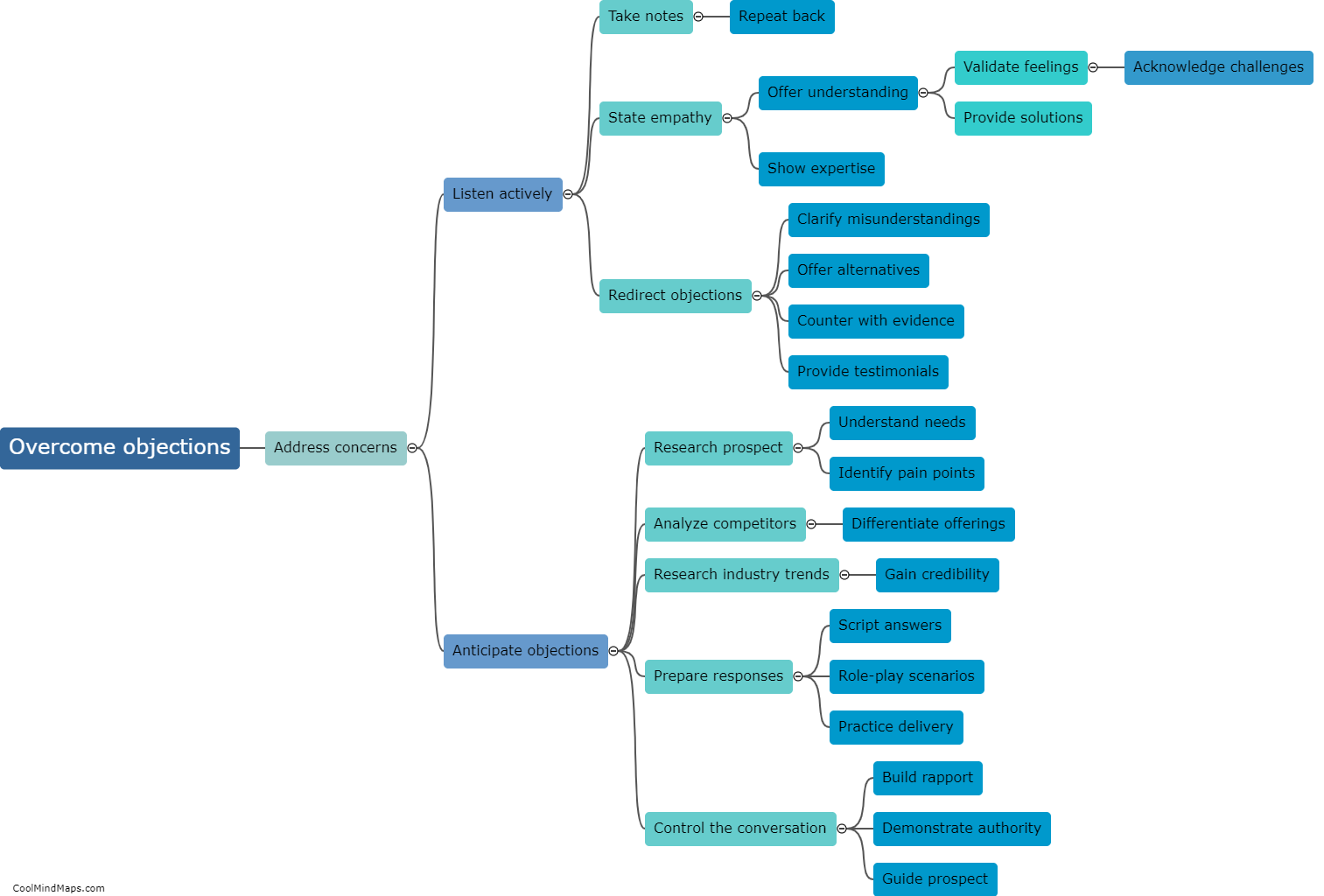
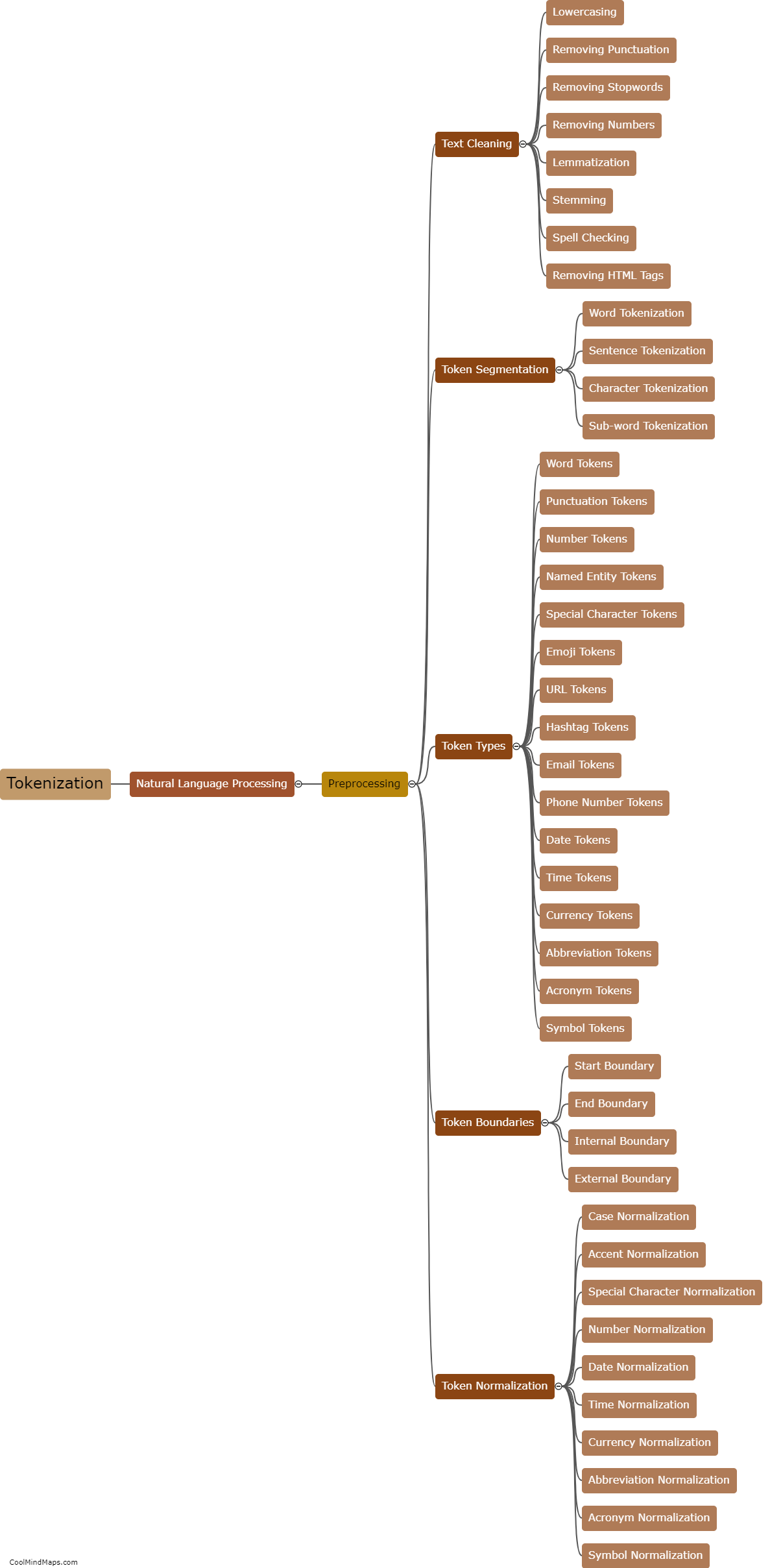
How does detailed tokenization work?
Detailed tokenization refers to the process of breaking down a given text into smaller units called tokens. Tokenization is a critical step in natural language processing and helps in analyzing language data effectively. Detailed tokenization involves considering not just individual words but also other elements such as punctuation marks, special characters, numbers, and even phrases as separate tokens. This level of tokenization captures fine-grained details and provides a more comprehensive representation of the text. It enables machines to better understand the language structure, identify syntactic and semantic relationships, and perform various language-based tasks, such as sentiment analysis, speech recognition, and machine translation.

This mind map was published on 1 August 2023 and has been viewed 120 times.